Skip connection이란?
deep architectures에서 short skip connections[1]은 하나의 layer의 output을 몇 개의 layer를 건너뛰고 다음 layer의 input에 추가하는 것이다. 이는 VGG[2]같은 기존의 model이 output만을 intput으로 사용되는 것과는 대비된다.

problem in tranditional architecture
skip connection을 이해하기 전에 왜 필요한지에 대해 알 필요가 있다. VGG와 같은 architecture를 설계할 때 깊을수록 더 나은 성능을 보인다. 하지만 깊이가 너무 정도 깊어진다면 오히려 성능이 하락하는 결과가 나타난다.
56-layer network는 전체 training 절차 동안 높은 training error를 갖는다. 20-layer network의 solution space는 56-layer의 subspace이지만, 놀랍게도 더 높은 error가 나타난다.
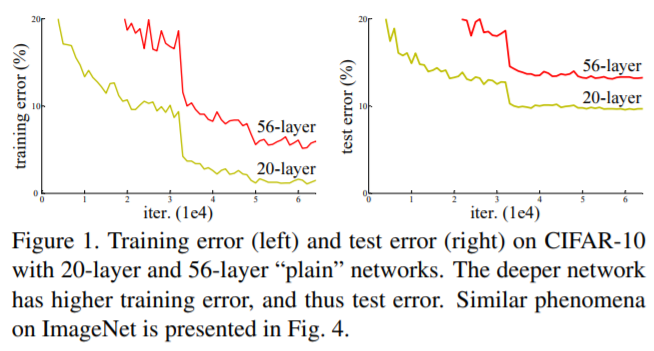
vanishing gradient problem
그렇다면 network의 깊이에 대해 "더 많은 layers를 사용하더라도 network를 우리가 원하는 대로 train될 수 있는가?"라는 의문을 갖는다. 여기서 문제가 되는 것은 vanishing/exploding gradient[2]다. 많은 layer를 통과하면서 gradient가 미세해지거나 매우 거대해진다면 수렴하기 어렵다. gradient 범위의 분포가 layer의 위치에 따라 상당한 차이를 보인다면 일부 layer가 많은 역할을 하기 때문에 모든 layer를 잘 활용하지 못할 것이다.
예를 들어 long chain of multiplication에서 chain을 따라가면서 1보다 작은 값을 곱하면, 매우 작은 결과를 얻는다. early layers에서 매우 작은 값이 나타난다.
how to solve the vanishing gradient problem
이러한 vanishing/exploding gradient 문제는 대부분은 nomalized initialization[4][5][7][11] 및 intermediate normalization layers[3]에 의해 해결되며, 수십 개의 계층이 있는 network가 backpropagation을 통해 gradient descent를 위해 converging을 할 수 있다. 하지만 깊은 network에서 이러한 방법을 이용하더라도 깊은 network에서 gradient vanishin 문제를 완전히 해결하지는 못한다.
깊은 network에서 발생하는 gradient vanishing 문제를 해결하기 위해 residual architectures[2]와 concatenation densely connected architectures[6] 두 가지 방법을 소개한다. short skip connections을 사용하는 resnet은 residual architectures다.
identity Mapping by Shortcuts
VGG와 같은 tranditional한 network에서 깊이는 많은 layers를 걸쳐 signal이 backpropagating할 때, vanishing gradienrts 문제에 의해 제한된다. 이 문제를 resnet에서는 short skip connections을 사용하는 residual architectures로 해결한다. 몇 개의 layer를 건너 뛰어 연결해 non-linearities를 추가하는 skip connections는 gradient가 layers를 건너뛰어 연결될 수 있는 shortcuts를 만들어 parameters를 network에 deep하게 업데이트 할 수 있다. short skip connection을 통해 몇 개의 layers를 건너뛰면 gradient가 원활하게 흐른다. 이는 updates를 안정화하며 gradient vanishing에 더 강력하기 때문에 converge가 보다 빠르다.
opinion and experimental results of this paper
하지만 앞서 말했던 것과 달리 resnet 논문[2]에서는 위에서 언급한 것과는 달리 optimization의 어려움이 vanishing gradients의 원인이 될 것 같지는 않다고 한다. plain networks는 forward propagated signals이 non-zero variances를 가지도록 하는 batch normalization으로 train 되며 propagate된 gradients backward는 BN와 함께 균형을 이루는 norms을 보인다는 것을 확인한다. 따라서 forward와 backward signal는 사라지지 않는다고 한다.
실제로 figure 4에서 shortcut을 사용하지 않는 34-layer plain net은 여전히 competitive accuracy를 달성할 수 있으며, solver가 어느 정도 작동함을 증명한다.
논문에서 명확한 설명은 없지만, deep plain networks가 기하급수적으로 낮은 convergence rates를 가져 training error 감소에 영향을 미칠 수 있다고 한다. 이러한 optimization 문제의 원인은 향후 연구될 예정이라고 언급했다.


Ensemble 관점에서 residual networks의 특성
그렇다면 skip connection이 어떤 역할을 해서 좋은 결과를 보이는 것인가?
Residual Networks Behave Like Ensembles of Relatively Shallow Networks[8]에서는 skip connections이 어떤 역할을 하는지에 대한 또 다른 견해를 소개한다.
[8]에서는 unraveled의 관점에서 본다면 residual networks는 다른 길이의 많은 paths의 모음으로 볼 수 있다고 한다.

dependence of residual networks
위 사진을 통해 residual networks의 perceived resilience은 paths가 서로 의존하는지 또는 어느 정도 중복성을 나타내는 지에 대한 의문을 제기할 수 있다.
일반적으로 neural network가 model structure의 급격한 변화에 견딜 수 있는지는 분명하지 않지만, layer를 삭제하면 모든 후속 layer의 input distribution이 크게 변경되기 때문에 깨질 것으로 예상한다.
[8]에서 실험한 lesion study에서 paths가 각 다른 것에 강력하게 종속되있지 않으며, ensemble 같은 행동을 보인다는 것은 밝힌다.
comparison of dependencies in traditional and residual networks
VGG와 residual architecture에서 random layer를 제거한 실험 결과를 보면 VGG의 경우 layer를 제거하면 random chance 수준으로 성능이 하락한다. 반면 residual network는 변동이 미미하다. down sampling 부분에서 제거했을 때 오히려 성능이 향상되기도 한다.


실험을 통해 test time에 residual networks의 single layers를 제거할 때 performance에 영향이 미세하다는 것을 관찰했다. VGG와 같은 traditional architecture의 layer를 제거하면, performance에서 급격한 저하가 나타나는 것과는 확연히 다른 결과다. 이는 dropout[9]과 비슷하다. dropout은 training 중 중에 개별 neurons를 삭제하면 기하 급수적으로 많은 network의 ensemble을 평균하는 것과 동일한 network가 생성한다.
why ensemble-like results are produced
residual networks는 layers 삭제에 강한 모습을 나타내지만, VGG는 그렇지 않다. unraveled view에서는 residual network를 표현하는 것에 대해 residual network를 많은 경로의 모음으로 볼 수 있다는 관점을 제시한다. VGG와 같은 전통적인 layer structure에서 각 처리 layer는 이전 layer의 출력에만 의존하는 반면에 residual network의 각 모듈 fi(·)는 이전 i-1 residual module의 가능한 모든 구성에서 생성된 다른 distribution의 2^(i-1)개의 mixture에서 data을 제공받는다.

deleting many modules from residual networks at test-time
paths의 모음이 ensemble처럼 동작한다면 residual networks의 test-time performance이 유효한 paths 수와 smoothly하게 연관될 것을 기대할 수 있다.

결과는 layer를 삭제하여 residual networks에서 경로를 제거하거나 layer를 reordering하여 layers를 제거하는 것이 성능에 크지 않고 완만한 영향을 미친다는 점에서 ensemble과 유사한 동작이라는 것을 보여준다.
conclusion
많은 사람은 resnet이 gradient vanishing 문제를 해결한다고 주장한다. 하지만 residual network는 network의 전체 깊이에 걸쳐 gradient flow를 보존하지 못해 vanishing gradient 문제를 완전히 해결할 수 없으며, 효과적인 paths를 shortening하여 매우 깊은 networks를 가능하게 한다고 생각할 수 있다. 실제 [8]에서 test의 결과에서 확인할 수 있듯이 early layer로 backpropagate가 진행될수록 gradient vanishing 현상이 나타난다. 이 문제점으로 실제 주요한 영향을 미치는 layer는 소수라고 추측할 수 있다. early layer의 gradient는 미세하므로, optimize 과정에서 early layer를 제거함으로서 성능을 유지하면서 inference time을 상당히 줄일 수 있을 것이다.
왜 long skip connections을 사용할까?
short skip connections는 shallow layers에서 gradient flow를 위한 shorcut을 제공하지만, 이외에 이유로 skip connection을 사용하는 경우가 있다. 고차원의 layer는 너무 추상화된 정보는 갖기 때문에 semantic segmentation 같은 task에서는 long skip connections가 사용된다. long skip connection을 사용하지 않는다면, 정보는 매우 추상적으로 반환될 것이기 때문에 long skip connection을 사용하지 않고 encoder 마지막 부분 layer의 작은 receptive field만 사용해 upsampling 과정을 진행하면, detail한 부분을 회복할 수 없다. structure의 표현은 보다 정확할 수 있지만, detail에 대한 표현이 부족할 것이다.
참고: global information(shape of the image and other statistics)은 "what"을 결정하는 반면에 local information은 "where" (small details in an image patch)을 결정한다.
how long skip connections work?
long skip connections은 downsampling 동안 잃는 spatial information을 회복하기 위해 contracting path에서 expanding path로 features를 skip하기 위해 사용된다. expanding path는 contracting path에서 다양한 resolution 수준으로 skip된 features를 merging함으로서 spatial information을 회복한다. skip connections은 semantic segmentation에 적합한 fully convolutional methode를 만듦으로서, network output에서 완전한 spatial resolution을 회복하는데 도움을 주는 것처럼 보인다.

summary of long skip connections
- layer의 size가 줄어들수록 receptive field가 증가해 detail한 부분보다 structure에 집중한다. 하지만 segmentation에서는 detail한 부분이 중요하기 때문에 encoder와 decoder가 long skip connections로 열결해야 한다.
- encoder에서 receptive field diameter를 넘어서는 pixel간의 독립성을 가정하여 image를 markov random field[13]로 모델링 한다고 추측한다.
- 환경에 따라 detail을 가장 잘 표현하는 receptive field 크기가 달라질 것이다. 적절한 receptive field의 크기는 픽셀간의 연관성이 적절하게 유지되는 범위를 고려해야 할 것이라 판단되는데, 여기서는 encoder-decoder 쌍으로 연결하는 것은 abstract의 level이 다르며, 각 object의 크기도 다양하기 때문이라 추측한다.
- skip connection을 사용하지 않고 encoder 마지막 부분의 작은 receptive field만 사용하면, detail한 부분을 회복할 수 없을 것이다. structure의 표현은 보다 정확할 수 있지만, detail에 대한 표현이 부족할 거라 예상할 수 있다.

Segmentation에서 short skip connections와 long skip connections의 비교
short skip connection은 training에 도움이 된다. converge가 더 빠르다. 이는 residual structure가 gradient vanishing에 더 강력하기 때문이다.
long skip connection은 encoder layer를 decoder와 연결하기 때문에 detail을 보다 잘 표현할 수 있다.
- 두 방법의 특징을 모두 잘 활용할 수 있다면 우수한 성능을 얻을 수 있다.

dice loss를 비교한 표를 보고 알 수 있는 사실:
- short skip connections가 long skip connection에 비해 빠르게 convergence한다.
- short and long skip connections 모두 사용했을 시 성능이 가장 우수하다.
- short skip connections를 이용한 결과도 long skip connections와 비견될만한 우수한 결과를 보여준다.

comparison of short and long for vanishing gradient problem
(a) short와 long 모두 사용했을 시 parameter update가 잘 이뤄진다. short를 제거한 (b)는 bottleneck 부분이 거의 update되지 않는다. bottleneck 부분이 깊고 short connections가 없는 (b)에서 center 부분에 vanishing gradient 문제가 심각하다. bottleneck을 줄여 shallow model (c)를 사용했을 시 update가 (b)보다 안정적이다. forward propagated signals이 non-zero variances를 가지도록 하는 batch normalization을 사용하지 않을 결과인 (d)에서 전체적으로 vanishing gradient 문제가 심각하다.

Short skip connections와 long skip connections 요약
short skip connections.
더 높은 성능을 얻기 위해 layers를 깊게 쌓을 때 vanishing/exploding gradient 문제를 겪을 수 있다. 많은 layers를 통과하면서 gradient가 미세해지거나 매우 거대해진다면, convergence가 어렵다.
layers를 깊게 쌓을 때 발생하는 vanishing/exploding gradient 문제는 대부분은 nomalized initialization 및 intermediate normalization layers에 의해 해결되어 수십 개의 계층이 있는 network가 backpropagation을 통해 gradient descent를 위해 converging을 시작할 수 있다. 하지만 깊은 network에서 이러한 방법을 이용하더라도 gradient vanishing 문제를 완전히 해결하지 못한다.
short skip connections를 이용하는 residual architecture에서는 vanishing gradient 문제를 short skip connections을 사용해 해결하려고 시도한다. 몇 개의 layer를 건너 뛰어 연결하는 skip connections는 gradient가 layers를 건너뛰어 연결될 수 있는 shortcuts를 만들어 parameters를 network에 deep하게 업데이트 할 수 있다. short skip connection을 통해 몇 개의 layers를 건너뛰면 gradient가 원활하게 흐른다. gradient vanishing에 더 강력하기 때문에 updates가 안정화되며 converge가 보다 빠르다.
long skip connections.
short skip connections는 shallow layers에서 gradient flow를 위한 shorcut을 제공하지만, 이외에 이유로 skip connection을 사용하는 경우가 있다. 고차원의 layer는 너무 추상화된 정보는 갖기 때문에 detail의 표현을 위해 semantic segmentation 같은 task에서는 long skip connections가 사용된다.
long skip connections은 downsampling 동안 잃는 spatial information을 회복하기 위해 contracting path에서 expanding path로 features를 skip하기 위해 사용된다. expanding path는 contracting path에서 다양한 resolution 수준으로 skip된 features를 merging함으로서 spatial information을 회복한다. skip connections은 semantic segmentation에 적합한 fully convolutional methode를 만듦으로서, network output에서 완전한 spatial resolution을 회복하는데 도움을 주는 것처럼 보인다.
long skip connection을 사용하지 않는다면, 정보는 매우 추상적으로 반환될 것이다. long skip connection을 사용하지 않고 작은 receptive field만 사용하면, detail한 부분을 회복할 수 없다. structure의 표현은 보다 정확할 수 있지만, detail에 대한 표현이 부족할 거라 예상할 수 있다.
References
[1]Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
[2]He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[3]Ioffe, Sergey, and Christian Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift." International conference on machine learning. PMLR, 2015.
[4] Y. LeCun, L. Bottou, G. B. Orr, and K.-R. Muller. Efficient backprop. ¨ In Neural Networks: Tricks of the Trade, pages 9–50. Springer, 1998.
[5] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
[6]Huang, Gao, et al. "Densely connected convolutional networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[7] A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv:1312.6120, 2013.
[8]Veit, Andreas, Michael Wilber, and Serge Belongie. "Residual networks behave like ensembles of relatively shallow networks." arXiv preprint arXiv:1605.06431 (2016).
[9]Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." The journal of machine learning research 15.1 (2014): 1929-1958.
[10]Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
[11] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
[12]Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[13]Liu, Ziwei, et al. "Deep learning markov random field for semantic segmentation." IEEE transactions on pattern analysis and machine intelligence 40.8 (2017): 1814-1828.
[14]Drozdzal, Michal, et al. "The importance of skip connections in biomedical image segmentation." Deep learning and data labeling for medical applications. Springer, Cham, 2016. 179-187.
'deep learning' 카테고리의 다른 글
| Stacked Hourglass Networks 리뷰 (0) | 2021.02.23 |
|---|---|
| EfficientNet 리뷰 (0) | 2021.02.19 |
| [Chapter 2]starGAN 코드 레벨 분석 (0) | 2021.01.28 |
| [Chapter 1]starGAN 리뷰 (0) | 2021.01.28 |
| [Style Trasfer]Instance normalization (0) | 2021.01.22 |



