Directory tree
저자의 starGAN repository[1]를 보면 starGAN 폴더에 4개의 핵심파일이 있다. dataLoader를 생성하는 data_loader.py, 전체 프로세스를 실행하는 main.py,generator와 discriminator가 정의되있는 model.py, 그리고 model을 build하고 training하는 solver.py 파일이다.

The whole process
전체 프로세스는 다음과 같이 세 개의 주요 절차로 요약할 수 있다. main.py의 main 함수에서 dataloader 생성하는 부분과 model build하는 부분, 그리고 training하는 부분이다.
이 세 가지 절차를 순서대로 살펴보겠다.

Create dataLoader
Multiple datasets can be used when training by using a mask vector mask vector를 이용할 수 있어, 하나의 generator를 training 할 때 여러 개의 dataset 사용 가능하다. dataloader의 생성은 get_loader 함수를 통한다.

get_loader 함수에는 transform 부분과 dataset 생성하는 부분, 그리고 dataloader를 생성해서 리턴하는 부분이 있다. transform에서 RandomHorizontalFlip은 일반적으로 많이 사용된다. CenterCrop과 Resize 부분은, 여러 개의 데이터셋을 이용하기 때문에 필요하다. CelebA[2] 같은 경우 image size가 178218, RaFD[3]의 경우 256256이다. 하나의 network를 이용하려면 input의 크기가 동일해야 한다. 비율과 크기를 맞추기 위해 center 부분을 crop하고 resize를 진행한다. center 부분을 crop함으로서 얼굴 부분을 더 강조할 수 있다.
다음으로 dataset 생성 부분을 보면, RaFD는 torchvision의 ImageFolder를 이용해 일반적인 방법으로 dataset을 생성한다. 반면에 CelebA의 경우 custom dataset을 이용하는데, dataset을 생성할 때 preprocessing 과정이 동반된다. 이 과정에서 40개의 labels 중 일부만으로 데이터셋을 생성한다.
RaFD의 경우 8개의 labels가 전부인데, Celeba의 경우에는 무려 40개의labels가 있다. 너무 많은 labels를 사용하면 다양성이 높아져 training의 난이도가 어려워져 결과적으로 생성된 image의 품질이 좋지 않을 수 있어 전체 labels 중 일부만 이용해야 한다고 추측한다.

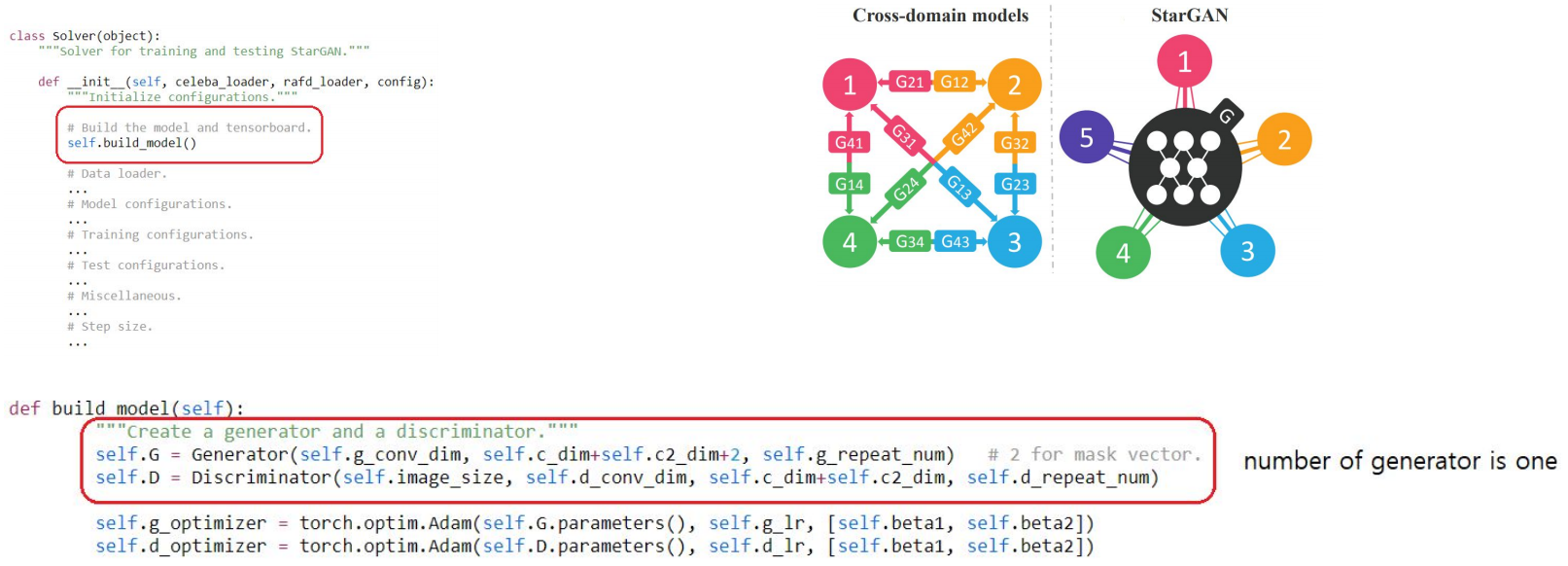
Build model
training과 testing을 위한 solver class를 이용해 instance를 생성하는 과정 (initialize)에서 model을 build 한다.

generator의 input으로 input image와 함께 domain정보를 이용하고, discriminator에서 domain을 예측하는 classifer를 추가함으로써 단일 generator로 다양한 도메인간 변환이 가능하다. 자세한 내용은 뒷부분에서 설명한다.
Generator architecture
starGAN[9]의 generator는 cycleGAN[10]의 architecture를 채택하는데, 일부 다른 부분이 있다. input에서 channel의 경우 image와 domain 정보가 channel-wise로 concatination되기 때문에 domain의 개수가 input의 channel 개수에 추가된다.
starGAN에서는 affine을 True로 사용하는데, cycleGAN에서는 instance norm의 affine을 False로 사용한다. affine=True면 output 값에 gamma를 곱하고 beta를 더한다. 여기서 gamma와 beta는 learnable parameter이며, beta는 bias 역할을 한다. 따라서 conv2d에서 bias가 필요없다.
batch normalization[4]을 사용하지 않고 instance normalization[6]을 사용하는 이유는 외견적 in-variance를 보존해, style을 변환하는 task에서 좋은 결과를 얻기 위해서라고 추측한다. 따라서 affine을 사용하면, 통계적 추정치로 인해, style 변환시 품질이 하락할 것이다. 그런데 왜 affine을 사용할까? 어떤 목적을 위해서? 그 부분에 대해 의문을 가졌지만 명확한 해답을 얻지 못했다.
또 다른 부분은 relu 부분이다. 코드 상에서 relu의 inplace가 true이다. inplace가 true이면 추가 출력 할당 없이 input으로 들어온 것 자체를 수정한다. inplace가 false면 x = relu(x)를 하고, inplace가 true면 relu(x) 형태로 사용한다. 이는 memory 사용량을 약간 줄일 수 있지만 미미한 수준이다.
최종 layer에서는 normalization된 input image의 값 범위가 -1~1이라 결과 값의 범위도 같게 하기 위해서 tanh 사용한다. 대부분의 generator에서 tanh 사용하지만 sigmoid를 사용할 수도 있을 것 같다.


추가적인 내용으로 cycleGAN은 unet[7]을 base로 사용했다가, 결과가 좋지 않아 resnet[8]을 사용했다. unet은 detail을 간직하며, bottleneck에서 저장할 수 있는 게 많지 않아, 급격한 변화가 가능하지만 두 domain이 비슷할 시 skip connection에 의존하는 경향이 있어 좋은 결과를 얻지 못한다. u-net은 불안정하기 대문에 bottleneck이 깊은 resnet architecture를 사용했다고 추측한다.
PatchGAN
discriminator는 pix2pix[9]에서 제시된 patchGAN의 방법을 사용한다. 기존 vanilaGAN의 경우 output은 real/fake 예측하는 단일 값인 반면 patchGAN의 output은 아래 사진과 같이 여러 값 (아래 사진에서는 16개)을 갖는다. 여러 값을 가진다면 input image의 receptive field가 제한된다. 단일 값을 이용해서 backprop을 진행하면 receptive field가 input image 전체이기 때문에 row frequency (structure)를 잘 capture할 수 있지만, high frequency (detail)은 잘 capture하지 못한다. detail한 부분을 잘 표현하기 위해 간단하게 attention을 가해주면 되는데, receptive field를 image의 부분으로 한정하는 방법이 있다. 이렇게 하면 부분마다 backprop을 진행해 detail한 부분을 더 잘 표현할 수 있다.

patchGAN에 대한 추가 설명. cycleGAN 같은 경우 얼룩말에서 일반말과 같은 변환을 수행할 때 스타일만 변환하고 shape는 변환하지 않는다. shape를 변환하는 task를 진행하면 바람직한 결과를 얻지 못한다.

아래 사진과 같이 고양이와 개 사이의 변환할 때 실패하는 것을 확인할 수 있다. 이는 shape를 변경해야하는 task이기 때문이다. 문제를 해결하기 위해 generator를 조정하려고 할 수 있지만, 간단하게discriminator를 조정해 바람직한 결과를 얻을 수 있다. 변환이 실패하는 것은 receptive field가 작은 영역만 다루기 때문이다. 작은 영역만 다루면 피부 또는 질감 같은 부분을 잘 capture 할 수 있다. 하지만 shape 같은 부분은 작은 영역으로 다루기 어렵다. 따라서 shape를 잘 capture하기 위해 receptive field를 늘릴 수 있다.

receptive field의 크기를 변경함으로서 성공적으로 변환이 수행된다. 하지만 receptive field의 크기가 크다면 비교적 detail한 부분을 잘 표현하지 못할 수 있다.

Discriminator architecture
discriminator는 두 종류의 output layer가 있다. adversarial loss를 계산하기 위해 real/fake에 대한 예측을 진행하는 Dsrc와 classification loss를 계산하기 위해 domain에 대한 예측을 진행하는 Dcls 부분이다.
코드를 보면 마지막 layer만 bias가 false이다. normalization을 사용할 때 후위 layer일수록 bias의 범위가 좁아져 영향이 미미하다. 반면에 normalization을 사용하지 않았을 때는 후위 layer라도 bias의 영향력이 줄어들지 않는것 같은데, starGAN의 discriminator에서 왜 bias를 false로 하는지 의문이 들었다. wgan-gp[12]에서 사용되는 gradient penalty가 norm의 역할을 어느정도 대체하기 때문이라 추측한다.

discriminator에서 cycleGAN과 다르게 normalization 방법이 사용되지 않는다. 이는 wgan-gp의 특성 때문인 것 같다. gradient penalty는 전체 batch가 아니라 각 입력과 관련해 critic의 gradient norm에 penalize하기 때문에 batch normalization을 사용한다면 training objective는 더이상 유효하지 않다. 문제를 해결하기 위해서 batch normalization을 제거할 수 있다.
논문에서는 입력간의 상관관계를 도입하지 않는 normalization 체계와 함께 사용한다고 한다. 특히 batch normalization을 위한 drop-in replacement로 layer normalization[5]을 추천한다. LN을 권장하는 이유는 image를 생성하는 upsampling의 경우 LN이 유리하기 때문일 거라 생각된다. 논문에서 제시된 결과가 단순히 image를 생성하는 것이 아닌 style 변화를 보여주는 결과였다면 외견적 in-variance를 보존하기 위해 IN을 권장했지 않았을까?
코드 상에서 batch normalization이 아닌 instance normalization[6] 또한 사용되지 않았다. 이는 gradient penalty 가 gradient norm이 1이 되도록 유도해 , gradient vanishing과 exploding의 발생을 방지하는 역할을 할 수 있는데, 이 부분이 normalization 역할을 부분적으로 대신하기 때문에 normalization을 사용하지 않기 때문이라 추측한다. gradient penalty를 이용해서 normalization 효과를 얻을 수 있기 때문에 따로 normalization을 적용하는 것이 방해요소로 작용할 수 있는 거 같다.
실제 테스트를 해보더라도 Instance normalization을 discriminator에서 이용할 때와 이용하지 않았을 때 FID score가 각 17.xx, 16.xx로 큰 차이가 없고 시각적으로도 구별하기 어려웠다. IN을 사용하더라도 문제가 발생하지는 않았다.
5.10. Bias Figure 5.3 suggests that the bias is not important for the layers 11, 13 and 15. Hence a model mno-bias is created which is identical to the baseline model m, except that the bias of layers 11, 13 and 15 is removed.
The mean test accuracy of 10 trained mno-bias is 63.74 % which is an improvement of 0.36 percentage points over the baseline. The ensemble achieves a test accuracy of 65.13 % which is 0.43 percentage points better than the baseline. Hence the bias can safely be removed.
Removing the biases did not have a noticeable effect on the filter weight range, the filter weight distribution or the distribution of the remaining biases. Also, the γ and β parameters of the Batch Normalization layers did not noticeably change. ([13]에서 발췌)


Training with Multiple Datasets
single_train과 multi_train이 있는데, single_train은 multi_train에서 mask vector 부분을 제외해 하나의 데이터셋만 이용할 수 있도록 한다. single_train은 단순히 multi_train의 열화판이라 생각해, train_multi에 대해서 정리했다.

training을 시작하기 위해 training과 testing을 위한 class인 solver를 이용해서 train_multi를 실행한다. num_iters 만큼 루프를 반복 epoch 단위가 아닌 iteration 단위를 사용하는 것은 dataset의 size가 크기 때문이라 추측한다. train_multi에서는 iteration 당 사용하는 datasets을 한 번 씩 이용해 training을 진행한다. training 과정은 input data를 preprocessing하는 과정, discriminator를 training하는 과정, generator를 training하는 과정과 나머지 (learning rate decay 등)를 하는 4단계로 이뤄져 있다. 중요하지 않은 4번을 제외하고 각 단계를 차례대로 살펴보겠다.

Preprocess input data
generator의 input으로 target domain과 input image를 channel-wise concatination을 통해 만든 input을 사용한다. channel-wise로 concatination하기 위해서는 domain의 height, width를 image의 height, width와 맞춰야 하기 때문에 각 label과 mask vector의 size를 128*128로 확장한다. 생성된 target domain을 input image와 chnnel-wise로 concatination해서 input으로 사용한다. 이 방법은 많은 중복이 발생해 최적이라고 보기 어렵다. 해당 팀은 이 방법이 최선이어서 사용했다고 한다.

Training the generator
wasserstein GAN objective with gradient penalty. wasserstein GAN[14]에서 discriminator를 critic이라 칭한다. n_critic은 discriminator를 몇 번 training하고 generator를 training할 지에 대한 변수이다. n_critic이 5라면 dicriminator를 5번 training하고 generator를 1번 training한다. 기존의 vanilaGAN의 경우 generator와 discriminator가 균형을 이뤄하하기 때문에 이러한 방식을 사용하지 않았다. 한쪽의 성능이 너무 뛰어나게 되면 적절한 feedback을 못받기 때문에 training이 불안정하다는 단점이 있었다. fake sample의 분포가 real sample의 분포와 동떨어져 있다면, 기존 vanilaGAN은 real이라고 예측하면 1, fake라고 예측하면 0이라 예측했다. 이렇게 되면 discriminator가 성능이 뛰어날 때 fake image를 0이라고 예측하는데, 이 값으로 backprop을 진행하면 vanishing gradients 문제가 발생한다. 이러한 문제점을 극복하기 위해 wasserstein GAN을 이용하는데, 이 방법은 real이면 1, false면 0이라는 값을 출력해 loss를 구하는게 아닌, wasserstein distance를 이용해 loss 를 구한다. wasserstein loss는 false data의 분포가 real data분포가 되려면 얼마나 이동해야하는지 그 비용을 loss로 사용하기 때문에, discriminator의 성능이 generator를 뛰어넘더라도 정상적으로 training이 진행될 수 있다.
training the generator. training the generator는 세 부분으로 나뉜다. original-to-target domain (a), target-to-original domain (b), backward and optimize (c).
첫 번째 부분은 생성된 fake image를 discriminator의 forward 과정을 통해 얻은 값을 이용해 loss를 계산하는 부분이다. real/fake인지에 대한 fake_loss, domain인 정확하게 분류했는지에 대한 cls_loss 이다.
두번 째 부분은 reconstruction loss를 구하는 부분이다. 이 부분은 fake image를 기존의 input image로 재생성하는 부분이다. input image와 reconstructed image가 최대한 같게 만들어주는 것이 목표다. 이 loss를 사용하는 것은 content는 보존하고, style만 바뀌길 원해서이다. fake image를 이용해서 input image를 다시 재생성하지 못한다면, 이는 content가 소실된 것을 의미하고, content를 구별할 수 없을 정도로 변했을 수도 있다. starGAN을 이용해 원하는 결과는 style만 변하는 것이므로, reconstructtion loss를 사용한다.
세 번째는 계산한 모든 로스를 더하는 부분이다. 이때 lambda라는 변수를 이용해 가중치를 부여할 수 있다. 예를 들어 reconstrion_loss에 lambda 값으로 10을 곱했다면, network가 reconstruction 부분에 대해 더 좋은 결과를 얻으려고 해, 변환 결과인 fake image에서 content 정보가 보다 잘 보존돼있을 것이다. 물론 한 부분을 강화함으로써 다른 부분에서 취약해질 수 있다.
마지막으로 backward와 optimize를 진행한다.


discriminator of vanilaGAN vs. wasserstein discriminator. vanilaGAN의 경우 discriminator는 마지막 layer에 sigmoid를 이용해 real이라고 판단하면 1에 가까운 값을 출력하고, fake라고 판단하면 0에 가까운 값을 출력한다. 이 때 discriminator의 성능이 너무 뛰어나면 generated image를 fake라고 판단해 0의 값을 출력한다. 0의 값을 이용해 backpropagation을 진행하면 vanishing gradients문제를 겪는다.
이처험 vanilaGAN의 Jensen–Shannon divergence (JSD)의 경우 연속적이지 않으며 모든 곳에서 미분이 가능하지 않다. 이러한 문제 때문에 vanilaGAN에서 generator와 discriminator의 균형이 매우 중요하다. 이 문제를 해결하기 위해 wasserstein GAN을 사용할 수 있다. wasserstein GAN의 경우 Earth Mover's Distance (EMD)의 경우 연속적이며 모든 곳에서 미분이 가능하다.
EMD를 이용할 경우 거리 문제를 사용한다. 한 분포를 다른 분포로 이동하기 위해 필요햔 최소비용을 구하는 문제인데, 모든 구간에서 연속적이고 거의 모든 곳에서 미분 가능하다. EMD를 사용하는 Critic (discriminator)은 generator보다 성능이 매우 뛰어나도 분포를 이동하기 위한 비용에 대한 loss를 사용하기 때문에 정상적으로 training이 진행되길 기대할 수 있다. 때문에 generator보다 discriminator이 더 높은 성능을 가지도록 discriminator를 generator보다 training을 많이 진행한다.

EMD를 loss function으로 사용하기 위해서는 미분이 가능해야 한다. 이 조건을 만족시키기 위해 연속성을 가져야 하는데, 이 때 lipchitz contraint를 적용한다. lipschitz continous functinon은 평균 변화율이 일정 비 이상으로 커질 수 없다. wasserstein gan에서는 lipschitz constraint를 만족하기 위해 clipping을 사용한다.

하지만 wgan 논문에서 clip은 명백히 terrible하다고 규정하며, 연구자들에게 이 방법의 개선을 적극 권장한다. Swiss Roll dataset에 대한 training 중 deep wgan critic의 gradient standard은 weight clipping을 사용할 때 explod하거나 vanish하지만 gradient penalty를 이용할 때는 그렇지 않다. weight clipping은 gradient penalty와 달리 weight를 clipping 범위의 끝으로 쏠린다. 따라서 clipping과 같은 terrible한 constraint가 아닌 soft한 constraing를 위해 gradient penalty를 사용하는 것이 추천된다.

미분가능한 모든 곳에서 gradients norm이 1이어야 1-lipschtiz이다. 다양한 contraint 방법이 있지만 wgan-gp 논문에서는 gradient norm을 직접 규제하는 것을 고려한다. discriminator에서 real data과 fake data 사이에 한 부분을 sampling해 그 값을 이용해 gradient penalty를 계산한다. 최적의 critic은두 분포 Pr, Pg의 결합된 점을 연결하는 gradient norm 1이 있는 직선을 포함한다는 있다는 사실로부터 동기부여했다. gradient norm constraint를 다루기 힘들다는 점을 감안할 때 이러한 직선을 따라 적용하는 것만으로도 충분해 보이며 실험적으로 좋은 성능을 얻을 수 있다고 한다. 두 분포 사이에 모든 값에 제약을 주려 하려면 많은 연산량이 필요함으로, monte-carlo technique를 사용할 수 있을 것 같지만, 단 하나의 값만 sampling해서 사용한다.


Training the discriminator
real images로 loss를 계산하는 부분, fake images로 loss 계산하는 부분, gradient penalty 계산하는 부분, backward and optimize 부분이 있다. real image의 경우 왼쪽 그림에서 보는 것과 같이 real/fake에 대한 예측과, domain에 대한 예측을 이용해 loss를 계산한다. fake image를 이용할 때는 real/fake 부분만을 이용해서 loss를 계산한다. gradient penalty 부분의 경우, wasserstein gan loss를 사용하기 위해 존재하는데, 이 부분을 real과 fake data 사이의 어떤 부분에서도 gradient norm이 1에 가깝게 하는 것을 목표로 한다. gradient norm이 1에 가깝게 함으로써 gradient의 vanishing과 exploding을 방지하는 효과를 얻을 수 있다. 이는 어느정도 normalization의 역할을 수행하는 것 같다. 마지막 부분은 구해진 loss를 더하고 backward and optimize를 진행한다.


참고자료
[2]Large-scale CelebFaces Attributes (CelebA) Dataset
[4]Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
[6]Instance Normalization: The Missing Ingredient for Fast Stylization
[7]U-Net: Convolutional Networks for Biomedical Image Segmentation
[8]Deep Residual Learning for Image Recognition
[9]Image-to-Image Translation with Conditional Adversarial Networks
[10]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
[11]Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
[12]Improved Training of Wasserstein GANs
[13]Analysis and Optimization of Convolutional Neural Network Architectures
[14]Wasserstein GAN
'deep learning' 카테고리의 다른 글
| EfficientNet 리뷰 (0) | 2021.02.19 |
|---|---|
| Skip connection 정리 (2) | 2021.02.02 |
| [Chapter 1]starGAN 리뷰 (0) | 2021.01.28 |
| [Style Trasfer]Instance normalization (0) | 2021.01.22 |
| Anomaly detection (0) | 2021.01.22 |



