Limitations of scale up in existing models
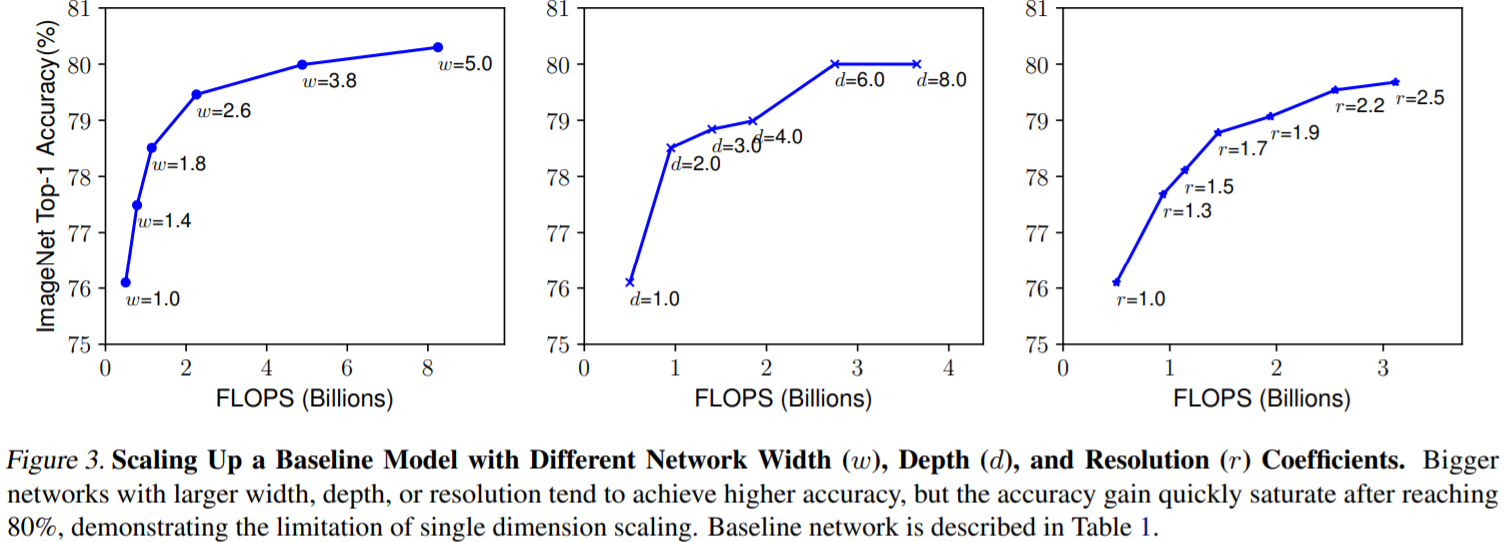
CNN architecture에서 depth, width, resolution을 확장하면 performance가 향상되지만, 제한된 자원을 이용해 더 높은 performance를 달성하기 위해 단순히 depth, width, resolution을 증가하는 방법으로는 한계가 있다. ResNet-1000은 ResNet-101보다 훨씬 많은 depth가 깊지만 빠르게 saturate 되기 때문에 performance 향상이 크지 않을 수 있다. 굉장히 큰 model은 diminish 현상이 나타난다.

Main contribution
EfficientNet[4]은 compound coefficient를 사용하여, depth, width, resolution를 균일하게 확장하여 보다 적은 parameter로 높은 accuracy를 얻는 방법을 제안한다. 이전의 이론적 [1][2] 및 경험적 [3] 결과는 모두 network width와 depth 사이에 특정 관계가 있음을 보여준다. [4] 보다 높은 accuracy와 efficiency를 위해서는 depth, width, resolution의 균형을 맞추는 것이 중요하다. 직관적으로 생각해보면, image resolution이 커지면, receptive field를 변경하고, fine-grained pattern을 잘 capture 하기 위해 width가 증가해야 한다.

Compound scaling method
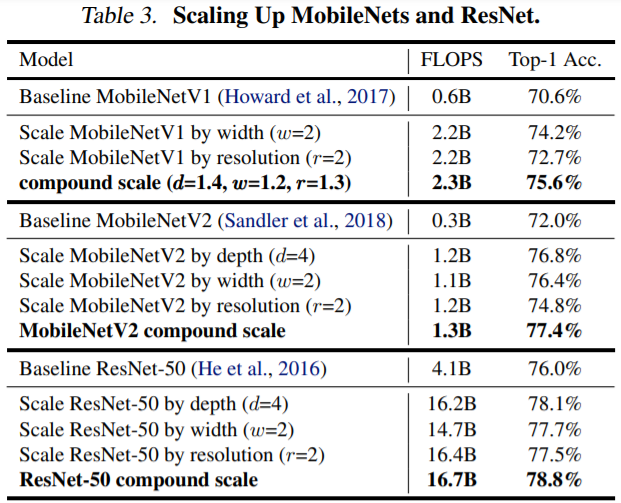
기존의 연구에서는 3가지 scaling의 coefficient를 임의로 증가해도 accuracy가 무조건 향상되지 않아 수동적인 tuning이며 과정이 필요했다. tuning을 진행하더라도 산출되는 model의 accuracy와 efficiency는 sub-optimal일 수 있다. 기존의 방법과 달리 EfficientNet은 적절한 depth, width, resolution을 찾기 위해 grid search를 사용해 alpha, beta, gamma를 구한다. beta와 gamma가 제곱인 것은, width와 height가 곱해지기 때문이다. 여기서 coefficient PI는 사용자가 정하는 값으로 scaling의 정도를 조절할 수 있다. 처음 alpha, beta, gamma를 구할 때는 coefficient PI의 값을 1로 고정한다. coefficient PI에 따라 EfficientB0~EfficientB7 중 필요로 하는 model을 사용할 수 있는데, 연산량의 문제 때문에 coefficient PI의 값 (1~7)마다 grid search를 진행해 alpha, beta, gamma 값을 구하지 않는다. coefficient PI가 1일 때 alpha, beta, gamma를 구한다. 만약 EfficientNetB0가 아닌 EfficientNetB7을 사용한다면 coefficient PI의 값만 7로 변경한다.
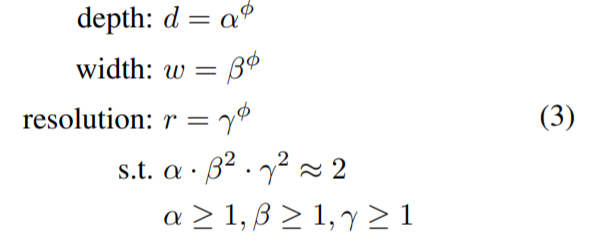
EfficientNet의 scale up 방법은 ResNet이나 MobileNet 등 다양한 architecture에 적용할 수 있다. 다만, 기본적으로 성능이 낮은 network를 사용하면 scale up을 하더라도 임계 성능이 낮을 수 있다. EfficientNet 팀은 neural architecture search를 사용해 MNasNet과 유사한 새로운 baseline network [4]를 개발한다.

Comparison results
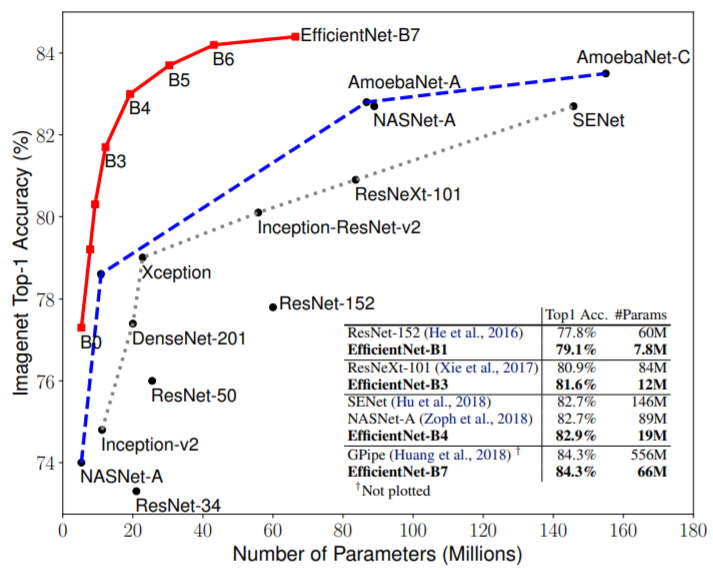
baseline network는 grid search를 통해 얻은 network width, depth, 그리고 resolution을 균형적으로 확장하는 compound scale coefficient에 따라 depth, width, resolution의 크기가 증가하고, accuracy가 향상된다. EfficientNet 논문에서는 coefficient PI에 따라 EfficientNetB0에서 EfficientNetB7까지 7단계로 분류한다. EfficientNetB0는 비슷한 accuracy를 갖는 ResNet-50와 비교해 parameters는 약 1/5이며, Flops는 약 1/11으로 큰 차이가 나타난다. 많은 task에서 사용되는 EfficientNet은 accuracy와 efficiency를 고려해 사용 환경에 따라 B0~B7 중 선택할 수 있다.

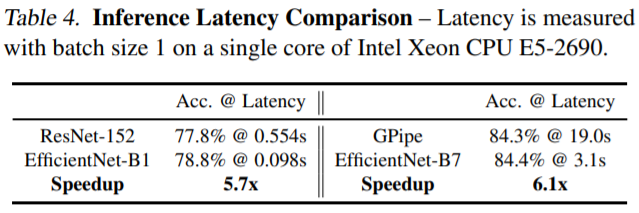
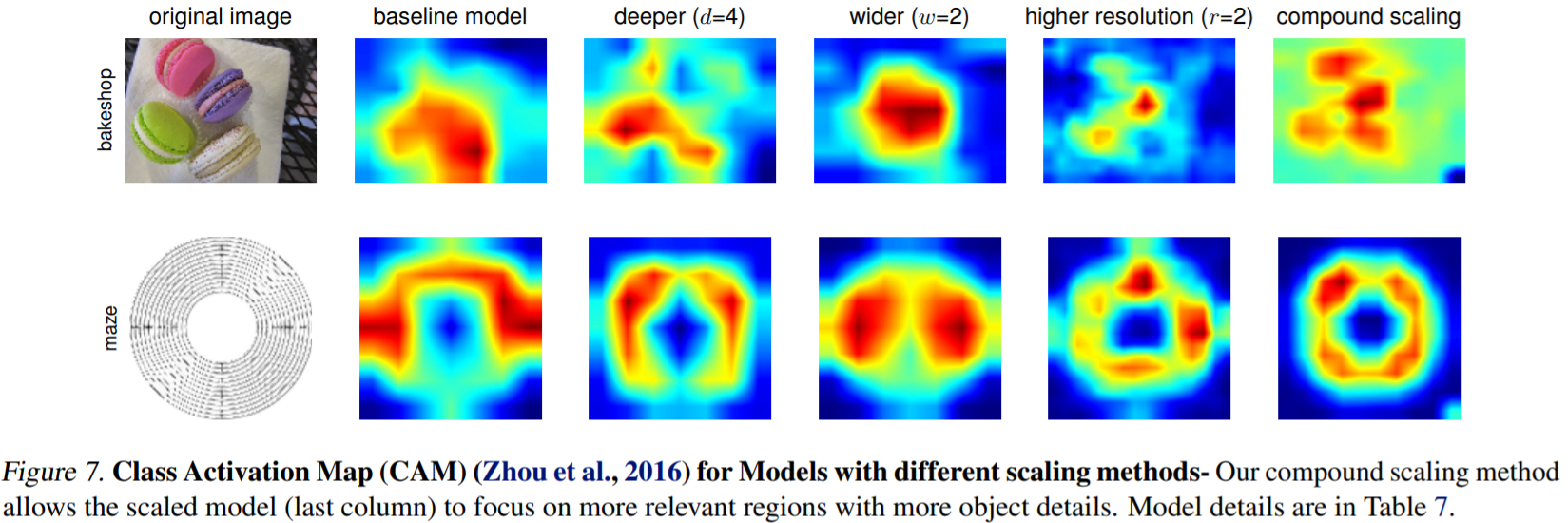
class activation map은 compound scaling의 우수성을 입증한다. compound scaling을 사용한 model은 더 관련성 있는 영역에 초점을 맞추는 반면, 다른 model은 detail이 부족하거나, 일부 object만 capture 한다.
비슷한 accuracy를 가진 model과 비교할 때 적은 parameters와 FLOPs를 갖는 것으로 나타난다. 특히 EfficientNetB7은 논문이 제시되었을 당시 state-of-the-art였던 GPipe의 performance를 능가한다. 표에서 볼 수 있는 것과 같이 accuracy와 efficiency 모든 부분에서 좋은 결과를 나타내는 EfficientNet은 여러 competition에서 가장 인기 있는 classification model이다. backbone으로 매우 훌륭한 장점을 지니고 있기 때문에, EfficientNet을 사용한다면 다양한 task에서 좋은 결과를 얻을 수 있다.

Advantages of using EfficientNet as a backbone
2012년부터 VGG [1], ResNet [2], MobileNet [3], Xception [4], 그리고 EfficientNet [5]과 같은 다양한 CNN을 기반으로 하는 architecture가 연구되고 있다. [8] efficientnet은 model scaling을 연구하고, 더 나은 성능을 위해 네트워크의 depth, width, resolution을 조정한 compound coefficient로 구성된다. classification에서 높은 성능과 적은 parameters를 가지는 efficientnet은 다양한 응용에서 이점을 갖는다.
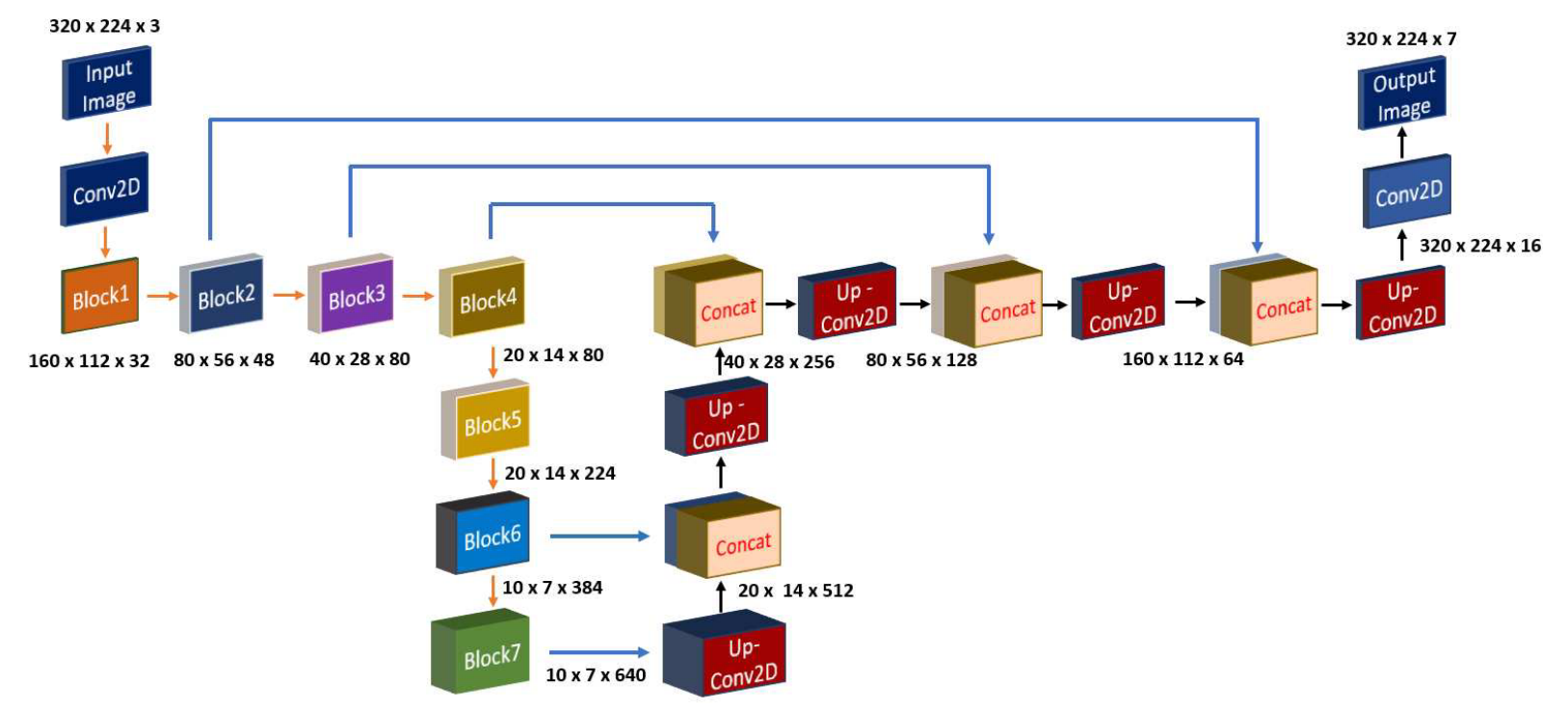
segmentation 같은 task에서 small feature map만을 이용해 upsampling을 하면 spatial information이 손상된다. spatial information을 효과적으로 회복하기 위해 우수한 성능을 보이는 efficientnet으로 feature extraction을 위한 encode를 사용하고, segmentation 결과를 생성을 위해 unet decoder를 사용한다. efficientnet과 같은 강력하고 효율적인 classification architecture를 encoder로 사용하면 model의 전반적인 성능이 향상된다. 우수한 segmentation 성능을 위해 high frequence (detail)와 low frequence (structure) feature를 decoder와 연결해 우수한 성능을 얻기 위해 efficientnet을 encoder로 사용할 수 있다.

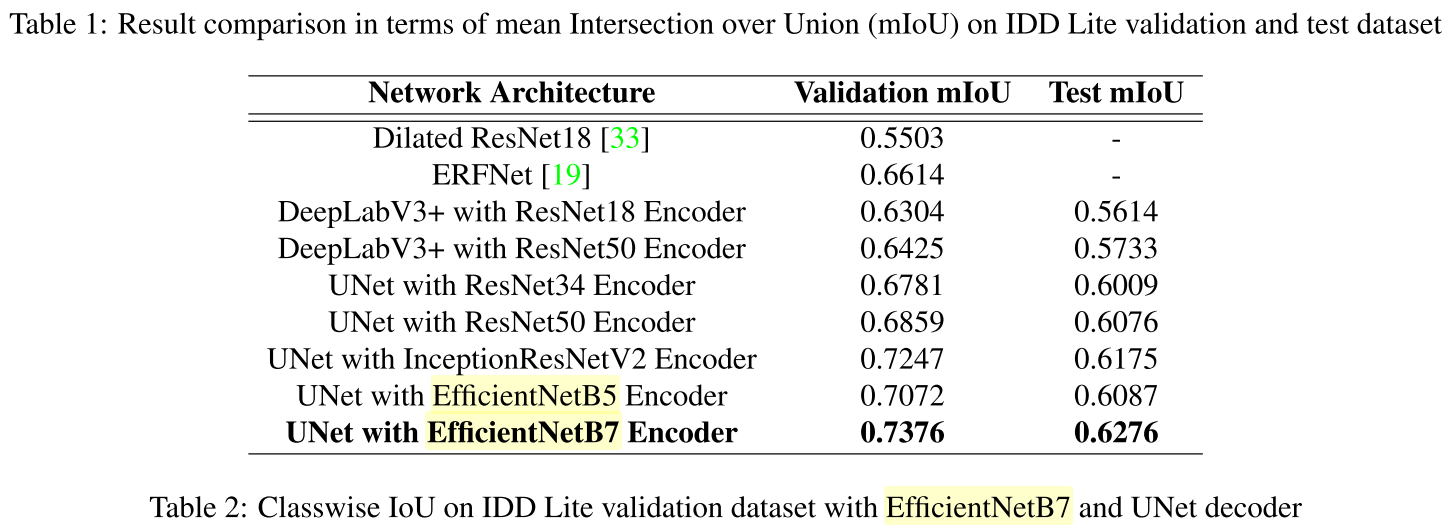
semantic segmentation task를 위해 다양한 architecture를 구현한 결과가 table 1에 요약되어 있다. table 1에서 UNet decoder가 DeepLabV3+[6] decoder보다 성능이 더 우수한 결과가 나타난다. UNet [7]의 encoder에서 low level feature이 더 많이 포함되었기 때문에 multiple object와 dense object가 있는 복잡한 장면을 분석하는데 유용하다. EfficientNetB7 model은 image classification을 위해 다른 architecture보다 성능이 뛰어나다.
References
[1]Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
[2]He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[3]Howard, Andrew G., et al. "Mobilenets: Efficient convolutional neural networks for mobile vision applications." arXiv preprint arXiv:1704.04861 (2017).
[4]Chollet, François. "Xception: Deep learning with depthwise separable convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[5]Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." International Conference on Machine Learning. PMLR, 2019.
[6]Chen, Liang-Chieh, et al. "Encoder-decoder with atrous separable convolution for semantic image segmentation." Proceedings of the European conference on computer vision (ECCV). 2018.
[7]Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
[8]Baheti, Bhakti, et al. "Eff-unet: A novel architecture for semantic segmentation in unstructured environment." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020.
[10]Raghu, M., Poole, B., Kleinberg, J., Ganguli, S., and SohlDickstein, J. On the expressive power of deep neural networks. ICML, 2017.
[11]Lu, Z., Pu, H., Wang, F., Hu, Z., and Wang, L. The expressive power of neural networks: A view from the width. NeurIPS, 2018.
[12]Zagoruyko, S. and Komodakis, N. Wide residual networks. BMVC, 2016.
[13]Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (pp. 6105-6114). PMLR.
'deep learning' 카테고리의 다른 글
| Deep Transfer Hashing for Image Retrieval 리뷰 (0) | 2022.02.23 |
|---|---|
| Stacked Hourglass Networks 리뷰 (0) | 2021.02.23 |
| Skip connection 정리 (2) | 2021.02.02 |
| [Chapter 2]starGAN 코드 레벨 분석 (0) | 2021.01.28 |
| [Chapter 1]starGAN 리뷰 (0) | 2021.01.28 |



