Anomaly detection란
anomaly detection이란 정상적인 동작에서 벗어난 observation을 식별하는 것이다. 비정상적인 데이터는 technical glitch 같은 critical incident나, 잠재적인 기회(소비자의 행동)를 나타낼 수 있다. 여기서 machine learning은 anomaly detection을 자동화하기 위해 점진적으로 사용된다.
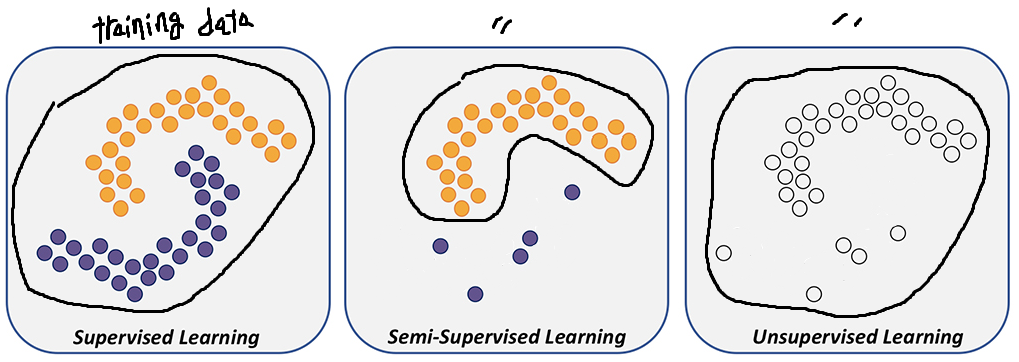
- anomaly detection은 3가지 categories(Supervised anomaly detection, Semi-supervised anomaly detection, Unsupervised anomaly detection)가 있다.
- anomaly detection은 intrusion detection, fraud detection, defect detection, fault detection, system health monitoring, event detection in sensor networks, detecting ecosystem disturbance에 자주 사용된다.

Anomaly detection에서 Unsuperviesed learning의 필요성
supervised learning을 이용한다면 가장 높은 성능을 얻는다. 다수의 obeject detection이나 segmentation task의 경우 image, label 쌍(pair)이 갖춰진 dataset을 이용하는 supervised learning 방식을 채택하며, data가 많을수록 더 높은 성능을 얻을 수 있다.
하지만 industry에서 anomaly detection에서는 기존 방식과는 다른 형태을 보인다. 일반적으로 industry에서 수백만개의 sample을 생성할 때 1~2개의 defective sample이 발생하는 경우가 많다. network를 이용한 training에서 100개의 data만을 이용하려면 상당히 많은 공정을 거쳐야 한다. industry에서는 defect sample이 극히 부족하고, defect-free sample과 defect sample의 분포과 심각하게 차이나기 때문에 supervised learning은 시도하기 어렵다.
supervised learning이 가능한 양의 defect sample을 얻더라도, industry에서는 고정된 형태가 아닌 여러 형태의 anomaly가 발생할 수 있다. 이러한 한계점으로 industry에서 supervised anomaly detection가 아닌 semi-supervised anomaly detection이나 unsupervised anomaly detection 방법을 사용할 필요성이 강조된다.
- supervised learning - train할 때 defect data와 detect-free data 모두 사용
- semi-supervised learning - train할 때 defect data만 사용하고 test 때 detect data와 detect-free data 사용
- Unsupervised Learning - defect data, defect-free data label이 없으며, 대다수가 defect-free data라 가정
기존 dataset을 대체하는 MVTec dataset
texture surface 검사를 위해 고안된 DAGM 2007은 2007 DAGM workshop에서 제안되었다. 인공적으로 생성된 dataset인 DAGM은 real world의 근사치로만 볼 수 있다. DAGM 2007의 annotation은 매우 coarse하며, texture가 매우 유사한 texture model에 의해 생성되었기 때문에 서로 다른 texture 간 variation의 차이가 매우 낮다. 따라서 evaluation에 제약이 있으며, 일반적인 industry에 적용될 거라 기대하기 어렵다. 실제 industry에서는 texture뿐만 아니라 object의 defect도 inspection하기 때문에 연구&개발을 위해 더 개선된 형태의 dataset의 필요성이 요구된다.

기존 dataset의 문제를 해결하기 위해 MVTec Software에서는 unsupervised learning을 위해 새로운 dataset을 제작했다. 해당 팀은 다양한 object 및 texture catefories의 high-resulution color image 5354장이 포함된 MVTec Anomaly Detection (MVTec AD) 데이터 세트를 소개한다. 여기서 train 할 때 defect-free image를 사용하고 test용으로 defect, defect image를 사용한다. anomalies는 scratches, dents, contaminations, and various structural chanes 등 다양한 유형의 defect 형태로 나타난다. (defect는 실제 industry inspection scenarios에서 발생하는 것과 같은 현실적인 anomalies를 생성하기 위해 수동으로 생성되었다)


Anomaly detection의 방법
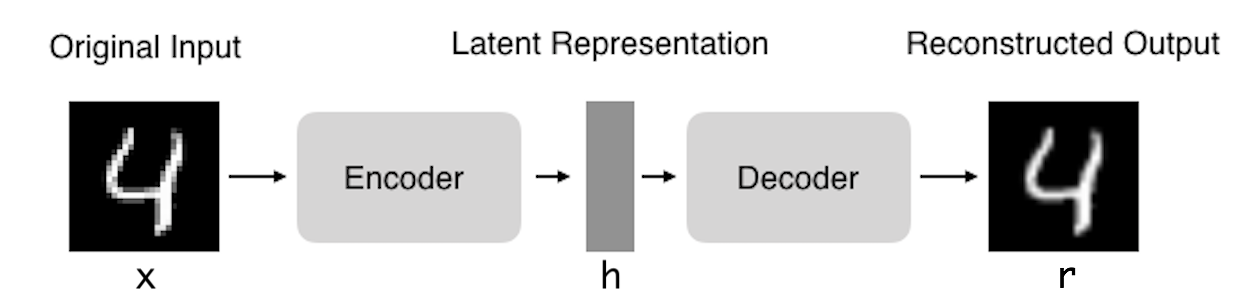
현재 anomaly detection에서 AutoEncoder, Generative Adversarial Networks (GAN) 등 deep architecture를 기반으로 unsupervised anomaly detection 연구가 진행되고 있다. 어떤 방법을 사용하느냐에 따라 좋은 결과를 보이는 task가 다르다. 하지만 현재 GAN를 사용하는 경우 좋은 성능을 얻지 못한다. 최근 논문을 보더라도 GAN을 이용한 경우는 비교적 드물며 주로 AutoEncoder를 기반한 방법이 사용되는 것 같다.
AutoEncoder를 사용하는 경우 output data가 input data에 근사하기를 원한다. defect-free data로만 training한 model을 이용해 test 할 때 defect data를 input으로 사용하더라도 output에서는 defect 부분을 제거한 결과가 생성된다. 이는, AutoEncoder가 중요한 feature를 추출하는 과정에서 불필요한 패턴(defect)을 제거하는 방향으로 encoding이 진행되기 때문이다. (AutoEncoder의 발전된 형태인 VAE, AAE를 사용했을 시 보다 뛰어난 성능을 보이기도 한다)


AutoEncoder에서 사용하는 loss인 L1, L2 loss는 image generation problems에서 blurry한 결과를 생성하는 문제가 있다.

최근에는 성능을 높이기 위해 patch 단위로 조작하는 형태의 방법이 빈번히 사용된다. L1 normalization과 L2 normalization은 high-frequency (detail)를 강조하지 못하지만, low frequencies (structure)를 보다 정확하게 capture 할 수 있기 때문에 high frequency를 강조하기 위해 structure에 대한 attention을 제약해 모델링할 수 있다. patch를 이용하는 방식인데 receptive field를 제약해 patch 단위로 backpropagation을 진행한다면, 더 detail한 image를 만들도록 feedback 할 수 있다.
아래 image를 통해 patch단위로 어떻게 수행되는지 시각적으로 확인할 수 있다. output matrix의 각 값은 image에서 해당하는 patch가 real인지 fake인지에 대한 확률을 표현한다.

Generic anomaly detection
일반적인 evaluation protocol은 기존 object classification dataset의 여러 calss를 outlier class로 임의로 label을 지정하고 나머지 class를 training을 위한 inlier 값으로 사용하는 것이다.
대표적으로 MNIST를 이용해 test하는 경우가 있다. inlier가 1이며, 나머지 숫자(0,2,3,4,5,6,7,8,9)가 outlier라고 가정하자. 성공적으로 training을 진행했다면, model에서 숫자 1 image를 넣으면 inlier라고 판단하고 1이외에 나머지 숫자 image를 넣으면 outlier라고 판단된다. 이러한 방식을 이용해 anomaly detection을 진행할 수 있다.
하지만 MNIST는 data의 작은 부분에서 변형되는 것이 아닌 shape 자체가 달라지는 dataset이기 때문에 실제 industry에서 사용할 model을 제작할 때 적합하지 못하다. industry에서 problem setting은 trainin data에 매우 가깝고 매우 작고 제한된 영역에서 미묘한 편차만 다른 image에서 novelties를 갖는 것이다.
결과적으로 좋은 알고리즘을 성공적으로 training 했다면 (아래)오른편의 image와 같이 normal과 anomalies의 분포가 분리된 형태를 보인다. 이렇게 된다면 threthold를 이용해 anomalies를 판단하는 기준을 정하기 쉽다. 왼편과 같은 결과가 나타난다면 anomalies를 구분하기 어렵다. 대다수의 경우 오른쪽의 image와 같이 명확하게 구분할 수 있는 분포를 원할 것이라 예상할 수 있다. (두 분포의 분리의 정도를 측정하는 방법인 AUROC를 이용해 anomaly detection의 성능을 측정할 수 있다)

참고자료
- Archives
- Introduction to Deep Anomaly Detection
- Bergmann, Paul, et al. "Improving unsupervised defect segmentation by applying structural similarity to autoencoders." arXiv preprint arXiv:1807.02011 (2018).
- Bergmann, Paul, et al. "MVTec AD--A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- Bergmann, Paul, et al. "Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
'deep learning' 카테고리의 다른 글
| EfficientNet 리뷰 (0) | 2021.02.19 |
|---|---|
| Skip connection 정리 (2) | 2021.02.02 |
| [Chapter 2]starGAN 코드 레벨 분석 (0) | 2021.01.28 |
| [Chapter 1]starGAN 리뷰 (0) | 2021.01.28 |
| [Style Trasfer]Instance normalization (0) | 2021.01.22 |



