실제 서비스 환경에서 모델의 거대한 연산량을 감당하기 어려울 수 있기 때문에 최적화 및 경량화의 중요성이 요구된다. knowledge distillation을 사용하면 제한된 크기와 깊이에서 준수한 성능을 얻을 수 있다. 좋은 teacher 모델은 one hot encoding 보다 세부적인 정보를 담고 있어 해당 정보를 잘 transfer 한다면 작은 모델로도 teacher 모델의 information flow를 흉내낼 수 있다. 복잡한 teacher 모델의 해시 기능은 one hot label 대신 supervised information으로 사용한다. teacher 모델에서 supervised information을 사용하여 모델을 보다 정확하게 training할 수 있다.
논문의 주요 contribution은 다음과 같다:
- teacher와 student 모델의 해싱 코드 분포를 최소화함으로써 복잡한 teacher의 hidden layer에서 작은 student 모델로 knowledge를 distill한다. image label보다 더 많은 supervised information를 포함하는 knowledge는 retrieval performance를 크게 향상할 수 있다. 추가적인 supervised information 없이 보다 강력한 얕은 네트워크를 training 하는 데 도움이 된다.
- retrieval 모델의 fully connected layer를 quantize 해 ternary model을 다른 degree로 구한다. retrieval performance loss가 적으면서 모델 크기를 compress할 수 있다.
- 두 개의 중요한 벤치마크 데이터 세트에 대한 실험을 통해 얇고 작은 모델이 다른 state-of-the-art deep hashing methods를 능가할 수 있다는 것을 알 수 있다.
Deep transfer hashing
본 논문의 해싱 기반 이미지 리트리버는 hashing based image retrieval, knowledge distillation, 그리고 model quantization 세 부분으로 구성된다.
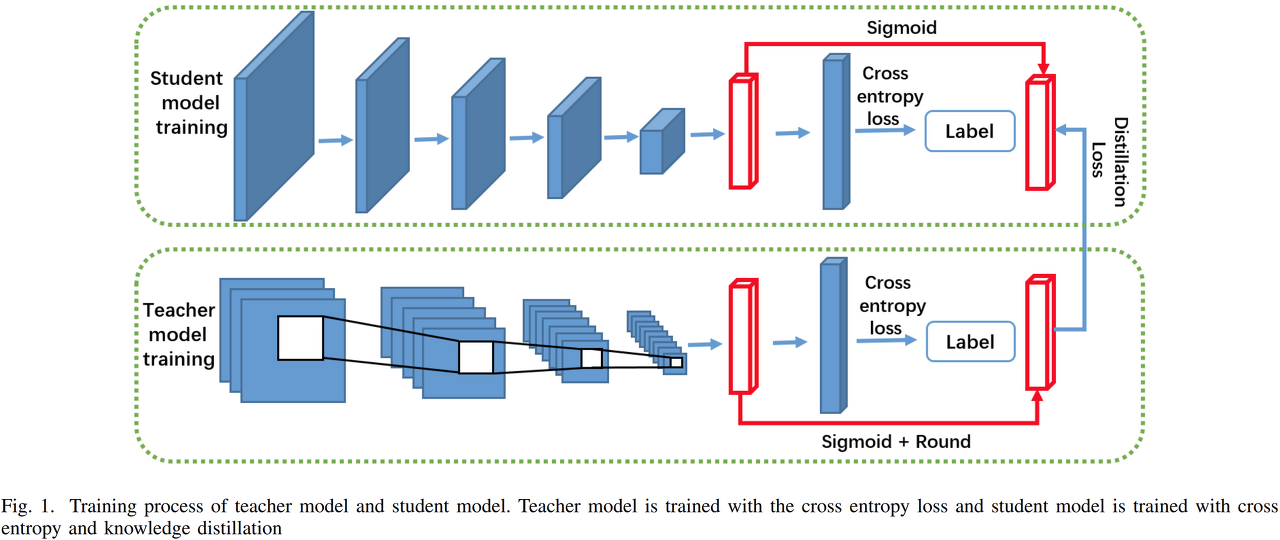
teacher 모델은 cross entropy loss를 이용해 training하고 student 모델은 cross entropy와 knowledge distillation을 이용해 training한다. 여기서 사용되는 해싱 기반 방법은 고차원 feature vector에서 높은 연산량을 감소하기 위해 사용한다. 해당 방법은 빠른 쿼리 속도와 낮은 메모리 소모 때문에 종종 사용되고 효율적인 기술이다. 해싱 기반 방법은 대규모 데이터베이스에서 검색해야 하는 경우 속도를 위해서 좋은 선택이 될 수 있다. 해싱 기반 방법은 단순히 fully connected layer의 output에 sigmoid 연산 후 round 연산을 수행한다.

DSH(Deep Supervised Hashing)은 아래의 그림을 요약된다. 수백만 개의 이미지를 가진 데이터베이스의 경우 검색에 많은 시간과 메모리가 소요될 수 있다. 이러한 문제를 해결하기 위해 image의 표현을 대략적으로 보존하는 이진 코드에 매핑한다. 효율적인 image retrieval을 위해 소개된 방법인 DSH는 쿼리 이미지와 트레이닝 이미지의 클래스가 같을 때 loss를 최소화하고 다를 때 최대화하는 형태다. 여기서 제시된 hashing based 방법이 feature extraction보다 10배 빠르다고 한다.

Quantization
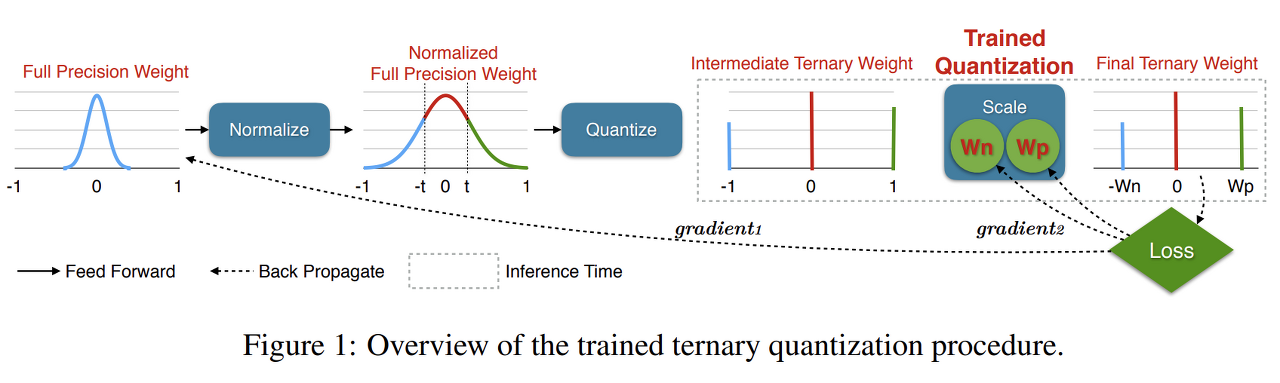
일반적으로 quantize는 full precision weight를 binary 또는 ternary 값으로 변환한다. 이렇게 함으로써 파라미터 저장 공간을 줄일 수 있고, retrieval 속도를 가속화한다. 본 논문에서 사용하는 ternary quantization은 convolution 또는 fully connected layers 가중치를 {-가중치, 0, +가중치} 세 부분으로 변환한다. -가중치, +가중치에 다른 scaling factor를 곱하는 비대칭성은 모델이 다양한 표현이 가능하게 한다. 더 나은 ternary network를 얻기 위해 training 시점에서는 full precision을 유지하고 inference나 test에서 ternary precision weights를 사용한다.
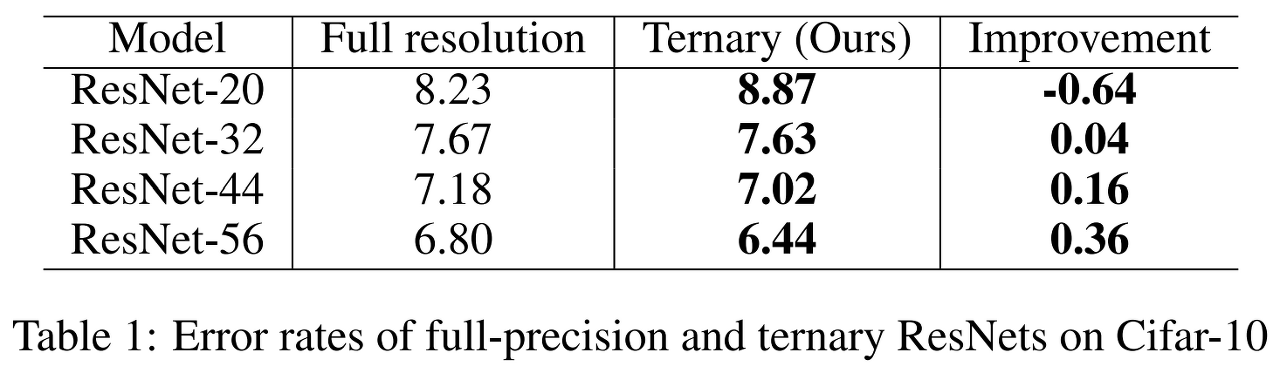
해당 방법은 zero weights의 비율이 너무 커서 모델의 크기를 지나치게 감소하는게 아니라면 accuracy 저하가 거의 없으며 32, 44, 56-layer ResNet에서 cifar-10 데이터 세트 사용시 오히려 accuracy를 향상할 수 있다고 한다.
대부분의 파라미터를 2 bit 값으로 변환한다면 네트워크는 약 16배가량 압축될 수 있다.

ternary quantization process
- full precision 가중치 정규화 범위를 -1에서 1 사이로 정규화.
- threshold를 사용해 -1, 0, 1 중 하나의 값으로 정규화된 가중치 quantize.
- two scale factors Wpl and Wnl를 이용해 최종 ternary weight 획득
wl은 full precision model l번째 layer의 max weights, t는 high-parameter
Instead of using a strictly optimized threshold, we adopt different heuristics: 1) use the maximum absolute value of the weights as a reference to the layer’s threshold and maintain a constant factor t for all layers: (출처: TRAINED TERNARY QUANTIZATION)
Experiments
Hamming distance가 작을수록 두 이미지의 유사성이 높아진다. 최종 이미지 목록을 얻기 위해 데이터베이스에 있는 이미지의 Hamming 거리 Di 순위를 오름차순으로 매긴다.
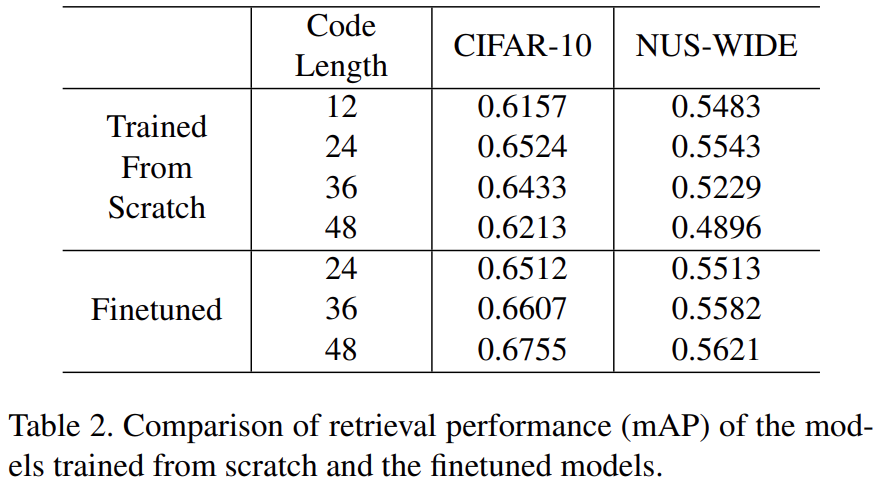
KD 사용했을 때와 사용하지 않았을 때 6% 정도의 차이가 난다. 하지만 teacher로 사용한 resnet을 보면 더 높은 성능을 보인다. 이는 DSH가 resnet50보다 얇고 작은 네트워크를 사용하기 때문일 것이다.


KD를 사용했을 때보다 사용하지 않았을 때 수렴하는데 더 적은 시간이 소요된다. KD를 사용하지 않았을 때는 100 epochs로 수렴하고, KD를 사용할 때는 400 epochs로 수렴한다. 해당 결과가 나타나는 것은 KD 모델의 output이 완전하지 않아 부정확한 결과를 포함하고 더 고차원적인 정보를 전달해주기 때문이라고 생각된다.
LD 적용하더라도 작은 모델은 큰 모델과 같은 성능을 얻기 어렵다. 경량화를 하면서 어느 정도 성능을 얻어내기 위해 사용할 수 있다. 절대적인 성능이 중요하다면 어느정도 모델 크기가 보장돼야 한다.


Opinion
논문에서 제안한 방법은 일반적으로 사용할 수 있지만 quantization 같은 경우 사실상 convolution layer를 quantize 한다면 극심한 성능 하락을 보일 수 있다. 따라서 fully connected layer만 quantize 하는 것이 최선으로 보인다.
convolution에서 fully connected layer보다 큰 하락을 보이는 건 kernel size가 적은 상태에서 제한된 값으로는 이미지의 특징을 표현하기 어렵기 때문이라 생각된다. fully connected layer는 불필요한 feature를 최소화하고 중요한 feature를 추출할 수 있을 정도로 많은 parameter를 보유하고 있음으로 quantization에 적합할 수 있다.

'deep learning' 카테고리의 다른 글
| Do Vision Transformers See Like Convolutional Neural Networks? 리뷰 (0) | 2022.02.25 |
|---|---|
| PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization 리뷰 (0) | 2022.02.24 |
| Stacked Hourglass Networks 리뷰 (0) | 2021.02.23 |
| EfficientNet 리뷰 (0) | 2021.02.19 |
| Skip connection 정리 (2) | 2021.02.02 |



