
NLP에서 지배적으로 사용되던 Transformer가 vision 분야에서도 적용되며 classification에서 SOTA를 뛰어넘고 있다.
ViT는 CNN을 넘는 성능을 나타내기도 했지만 매우 큰 데이터가 필요하다는 제약사항이 있다. 주로 많이 사용되는 거대한 데이터셋인 ImageNet으로도 ViT의 성능을 온전히 끌어내기 어렵다. 구글에서 사용하는 JFT 데이터셋과 같은 매우 거대한 데이터셋을 사용해야만 비로소 기존 CNN SOTA를 뛰어넘는다.
CNN은 어떻게 적은 데이터만으로도 잘 학습하는지에 대한 해답을 inductive bias에서 찾는다. 위키피디아의 정의에 따르면 inductive bias란 "학습 시에 만나지 못했던 상황에 대하여 정확한 예측을 하기 위한 추가적인 가정"이다.
CNN은 locality와 translate equivariance와 같은 inductive bias가 있어 학습하지 않은 데이터의 문제를 쉽게 해결할 수 있는 visual representations를 얻을 수 있다. 반면에 transformer는 모든 픽셀 간의 상관관계를 파악해야 하므로 학습난이도가 높다. 복잡도가 높은 모든 픽셀 간의 관계를 나타내기 위해서는 큰 모델과 데이터셋이 필요할 수 있다. 매우 거대한 데이터셋으로 학습할 때 복잡한 상관관계를 학습할 수 있는데 지역적 정보의 학습을 강제해 복잡도를 낮추기 위해 ViT에 CNN을 접목하는 hybrid ViT-CNN model을 설계할 수 있다.
Introduction
CKA similarity (paper, code)를 사용해 유사도를 비교한다.
본 논문의 목표는 ViT의 표현 방식, image task를 해결하는 방법에 차이가 있는지 이해하는 것이다.
- ResNet과 달리 ViT가 모든 레이어에 걸치 균일한 representations을 갖는다는 것을 보인다. 이러한 결과가 나타나는 것은 ViT의 residual connections이 하위 layers에서 상위 layers로 feature가 강력하게 전파하는 역할을 하기 때문이다.
- ViT는 CNN을 사용해 local information이 하위 레이어에서 강제로 하드코딩되는 ResNet과 달리 하위 레이어에서 global information을 사용한다. 이 때문에 spatial information을 활용이 달라진다. 추가적으로 spatial localization과 classification method 간의 연관점을 찾아 왜 input spatial information이 잘 보존되는지 조사한다.
- ViT의 균일한 내부 구조에서 Skip connection이 ResNets보다 ViT에 더욱 큰 영향을 받아 performance와 representation similarity가 크게 변한다.
높은 quality intermediate representations에 대한 중요성을 나타내는 linear probes study와 함께 transfer learning에서 데이터셋 크기의 영향을 연구한다.
Representation Structure of ViTs and Convolutional Networks
ViT는 grid-like의 패턴이 뚜렷하고 하위 계층과 상위 계층 간의 유사성이 큰 비교적 균일한 계층 구조로 되어 있다. ResNet은 하위 계층과 상위 계층 사이의 유사성이 적고 명확한 구분이 있다. 즉, ViT 하위 계층은 ResNet의 하위 계층과 다른 방식으로 표현을 계산하며 ViT는 하위 계층과 상위 계층 간에 표현을 더 강력하게 전파한다.

ViT 계층의 마지막 1/3는 모든 ResNet 계층과 유사도가 낮다. 이 계층 집합이 주로 CLS 토큰 표현을 다루는 것이기 때문이라고 추정한다.

Local and Global Information in Layer Representations
아래 figure에서 가장 낮은 두 계층과 가장 높은 두 계층에 대한 평균 attention 거리에 따라 정렬된 헤드를 아래 figure에 표시한다. 각 self-attention layer는 여러 개의 self-attention heads로 구성되며, 각 헤드에 대해 쿼리 패치 위치와 쿼리 패치 위치 사이의 평균 거리를 계산한다. 하위 계층은 지역 및 전역적 모든 정보에 영향을 받으며 상위 계층은 전역 정보를 주로 반영한다.

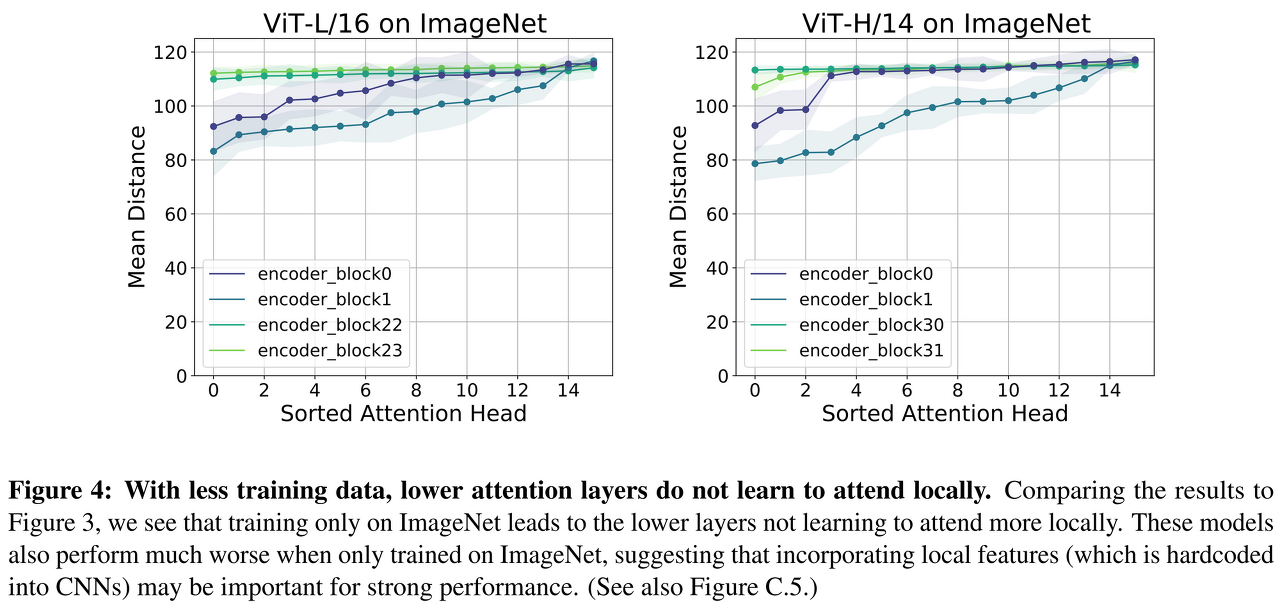
ViT는 하위 계층에서 지역적인 영향을 받도록 하드 코딩된 CNN과 달리, 가장 낮은 layers는 self-attention layers는 local head(small distances)와 global head(large distances) 모두 포함한다. 상위 계층에서는 모든 self attention head가 전역적이다. ViT는 하위 layers에서 CNN보다 더 많은 전역 정보에 접근할 수 있다.
사용하는 데이터는 지역적 및 전역적 정보를 모두 사용한다. 지역적인 정보를 학습했다는 것은 전역 데이터를 보고 학습하는 ViT가 이미지의 특징을 잘 표현하도록 학습했다고 생각할 수 있다. 데이터가 충분하지 않으면 ViT가 이전 계층에서 로컬로 영향을 미치는 방법을 배우지 못한다.
ImageNet에서 학습한 block은 mean distance 값이 전체적으로 높은 편으로, 거대한 데이터셋인 JFT를 사용했을 때 학습하는 지역 정보를 학습하지 못하는 것으로 보인다. 해당 결과는 CNN architectures에서 하드 코딩된 지역 정보를 초기에 사용하는 것이 강력한 성능을 위해 중요하다는 결론을 내릴 수 있다.
Representation Propagation through Skip Connections
유사성에 대한 각 하위 집합에 대한 평균 거리를 plot 하면 mean attention distance가 커질수록 유사성이 단조롭게 감소하는 것이 명확히 보인다. ResNet의 하위 계층 표현은 ViT의 로컬 어텐션 헤드에 해당하는 표현과 가장 유사하다. 아래 figure에서 가장 로컬로 attend 하는 heads(가장 작은 평균 거리)에서 가장 크게 attend 하는 전역 heads(가장 큰 평균 거리)에 이르는 첫 번째 인코더 블록에서 ViT attention heads의 subset을 취한다.

아래 figure에서 더 많은 전역 정보에 대한 접근은 ResNet의 lower layers에서 local receptive fields에 의해 계산된 것과 특징으로 이어진다는 결론을 내릴 수 있다.
피처 맵의 use center location의 gradient의 절대값으로 다른 레이어의 effective receptive field를 측정한다. ViT에 대한 하위 레이어 effective receptive field가 ResNet에서보다 실제로 더 크다. ResNet effective receptive field는 점차 증가하는 반면, 강한 skip connection으로 인해 ViT는 center patch에 의존한다. ViT는 전역 정보에 대한 접근으로 인해 하위 계층에서 ResNet에 대한 다양한 표현을 학습한다. ResNet effective receptive field는 지역적으로 점진적으로 확장되고 처음과는 전혀 다른 형태가 되지만, ViT effective receptive field는 로컬에서 전역으로 빠르게 확장된다. ViT 표현의 매우 균일한 특성(그림 1) 또한 lower representation이 높은 계층으로 순조롭게 전파된다는 것을 암시한다. appendix C, attention sublayers에서 skip connection이 없을 때 center patch에 대한 receptive fields의 의존도가 훨씬 낮다는 것을 알 수 있다.

skip connection의 영향력을 알아보기 위하여 norm ratio ∥zi∥/∥f(zi)∥를 측정한다.
CLS에서 spatial token propagation로의 phase transition과 함께 전체적으로 ViT에 대한 훨씬 더 높은 norm ratio를 관찰한다.
네트워크의 전반부에서 CLS token(token 0) representation은 주로 skip connection short branch(high norm ratio)에 의해 전파되지만, spatial token representations은 long branch(low norm ratio)에서 크게 기여한다. 이는 하위 계층에서 cls가 activation을 통해 업데이트되는 부분이 적어 큰 역할을 하지 않지만 상위 계층에서 cls가 각 토큰의 문맥을 통해 결과를 도출하는 주된 역할을 한다고 생각한다.

skip connection이 없는 middle block의 경우 4%의 성능 저하가 관찰된다. 블록 i에서 skip connection 없이 학습된 ViT 모델은 block i 전/후 계층 간에 representation similarity가 거의 보이지 않는다. 아래 figure는 ViT의 standard uniform representation structure에서 skip connection의 중요성을 보인다. 이 결과는 skip connection은 몇 개의 계층을 제거하더라도 성능 하락이 크지 않고 완만한 영향이 있는 resnet에서 kip connection을 제거했을 때와는 확연한 차이가 있다.

cls 토큰으로 학습을 진행하는 경우 다른 토큰이 취합하는 전역 정보는 희소하기 때문에 individual token evaluation에서 상당히 낮은 accuracy를 보인다고 생각된다. 반면 GAP을 사용해 학습하는 경우 마지막 레이어의 모든 레이어를 사용해 cost를 계산하고 학습을 진행하기 때문에 모든 토큰이 전역적인 정보를 갖고 있어 individual token evaluation의 성능이 높게 나온다고 추측한다.
cls 토큰으로 학습하고 cls 토큰을 제외한 토큰들로 GAP을 통해 classifier를 붙여 10-shot 학습을 진행한 경우에 성능이 낮게 나오는 것을 관찰할 수 있다. 해당 결과는 cls 이외의 토큰은 전역 정보를 적절히 얻지 못하기 때문에 cls 토큰에 의존하는 경향이 강하기 때문이라 생각된다.

Spatial Information and Localization
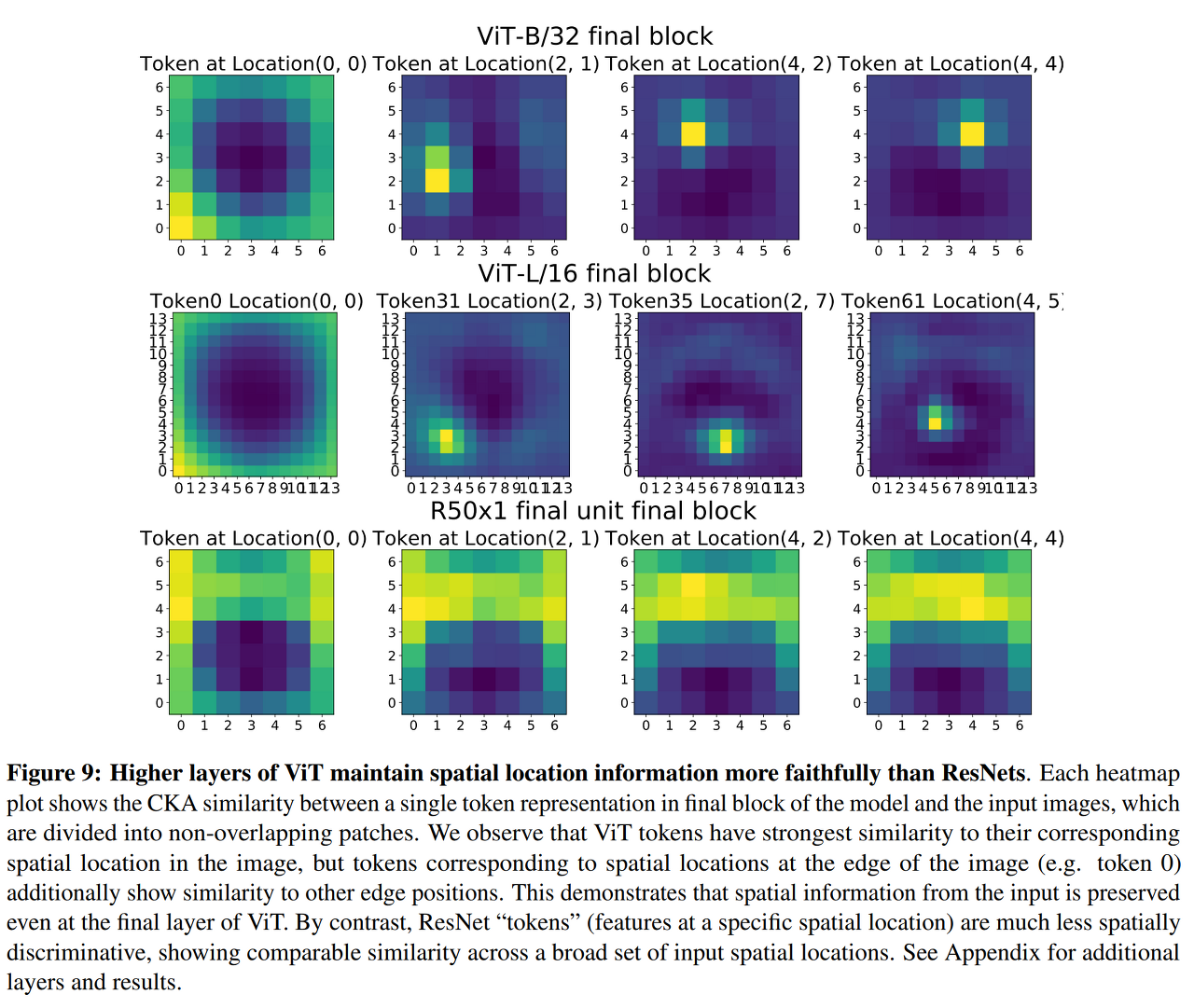
ViT 토큰에는 해당하는 입력 패치가 있으며, 따라서 해당 입력 공간 위치가 있다. ResNet의 경우 token representations을 particular spatial location의 모든 컨볼루션 채널이 되도록 정의한다.
이미지의 가장자리에 있는 위치에 해당하는 토큰이 edge image patch와 유사하지만, 내부 위치에 해당하는 토큰은 해당 이미지 패치와 가장 유사한 localization되어 있다.
아키텍처 간의 이러한 분명한 차이에 영향을 미치는 한 가지 요인은 ResNet이 글로벌 평균 풀링 단계로 분류하도록 훈련되지만 ViT는 별도의 분류(CLS) 토큰을 가지고 있다는 것이다. 아래 figure는 글로벌 평균 풀링이 실제로 상위 계층에서 localization을 감소시킨다는 것을 입증한다. CLS 토큰 대신 글로벌 평균 풀링(GAP)을 사용하여 교육할 경우 ViT는 localization이 명확하지 않다.

Effects of Scale on Transfer Learning
lower layer representation은 데이터의 10%와 similarity가 높지만, higher layers와 larger models는 유사한 표현을 학습하기 위해 훨씬 더 많은 데이터가 필요하다. 이는 더 큰 모델의 경우 더 큰 데이터 세트가 고품질 중간 표현을 학습하는 데 특히 중요하다는 것을 시사한다.
더 큰 ViT 모델이 ResNet보다 훨씬 강력한 중간 표현을 배운다

Conclusion
ViT는 전역 정보를 활용해 inference를 진행한다. 이는 지역적인 영역이 하드코딩된 CNN과 대비된다. 전역 정보를 활용함으로써 이미지 전체의 픽셀 간에 상호관계를 잘 파악할 수 있다. 복잡한 상호관계를 파악하려면 많은 데이터와 파라미터가 필요하다. 하지만 현실세계에서 많은 데이터를 구하기는 어렵고 많은 파라미터를 사용하려면 좋은 하드웨어가 필요하다. 여러 제약으로 실제로 트랜스포머 모델이 좋은 성능을 보이는 경우는 많지 않을 수 있다.
CNN의 단점을 극복할 수 있다는 점에서 충분히 고려할 만하다. CNN은 지역적인 영역을 이용하도록 하드코딩되어 있어 구조보다 질감에 중점을 두고 inference를 진행하는 경향이 있다. 후위 레이어로 갈수록 receptive field가 커져 전체적인 구조를 파악하는데 비중이 높아질 거라 예상할 수 있지만, 실제 실험 결과를 보면 레이어를 지나면서 receptive field가 커지더라도 지역적인 영역을 중점을 두는 것을 알 수 있다. cycleGAN과 같은 generative model에서도 풍경 변화와 같은 task에서는 모델이 잘 동작하지만, 개↔고양이 변환과 같은 task에서는 예상대로 이미지가 변하지 않고 질감적인 부분만 변경된다. 이와 같은 한계를 가진 CNN을 뛰어넘기 위해서 ViT를 대안으로 제시할 수 있다.
'deep learning' 카테고리의 다른 글
| PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization 리뷰 (0) | 2022.02.24 |
|---|---|
| Deep Transfer Hashing for Image Retrieval 리뷰 (0) | 2022.02.23 |
| Stacked Hourglass Networks 리뷰 (0) | 2021.02.23 |
| EfficientNet 리뷰 (0) | 2021.02.19 |
| Skip connection 정리 (2) | 2021.02.02 |



